Routine care generates large volumes of medical text that contain valuable information about patients. However, the wording, content and structure of medical documentation can vary greatly between different institutions, making it unusable for digital programmes or analysis across different locations. In the SMITH consortium, the NLP project has addressed this problem by publishing guidelines for preparing medical texts so that they can be used for medical research and care, using methods of natural language processing (NLP).
In all German hospitals, doctors’ letters are written at the time of transfer and discharge to provide information about the patient to the doctors who continue to treat him or her. These letters are an essential part of the medical record and contain information about the reason for the treatment, details of the patient’s medical history, allergies, previous illnesses, family diagnoses, therapies already carried out, medications prescribed to date and also information about further treatment. This information can be of great value not only to the doctors treating the patient, but also to medical research and to the patients themselves.
In order for these medical documentation texts to be used across sites, they must be readable by digital programmes. However, the wording of medical texts is highly dependent on the institution, the medical speciality and also the person who writes them. In addition, they are not standardised either structurally or in terms of content. Automated capture of details in texts such as doctors’ letters and discharge summaries, such as descriptions of medicines, their frequency of use (daily, three times a day) or form of administration (as tablets, drops) is therefore hardly possible without prior preparation.
Automated text analysis methods can make the content of such texts usable for technical information systems as well as for treating doctors and patients. However, this requires that such NLP systems have access to sufficient text material to enable automatic analysis.
With the help of special computer programmes, so-called annotation tools such as Brat or INCEpTION, trained personnel mark text passages in manual steps according to certain content specifications. These markings, also known as annotations, contain clues about the structure and content of the texts and form the basis for statistical models on which modern NLP systems base their analyses. The creation of such annotations is governed by annotation guidelines. During the first funding phase of the Medical Informatics Initiative (MII), several such guidelines were developed for the annotation of German discharge summaries. They focus on the following tasks:
1) Structures of text passages that indicate whether a text passage describes, for example, a salutation, an anamnesis or the administration of medication, or the course of a hospital stay.[1]
2) Person-identifying characteristics or all descriptions that allow conclusions to be drawn about an individual patient and must therefore be subsequently anonymised for data protection reasons (e.g. personal names, address data or dates).[2]
3) Descriptions of key medical categories such as diagnoses, symptoms and findings;[3]
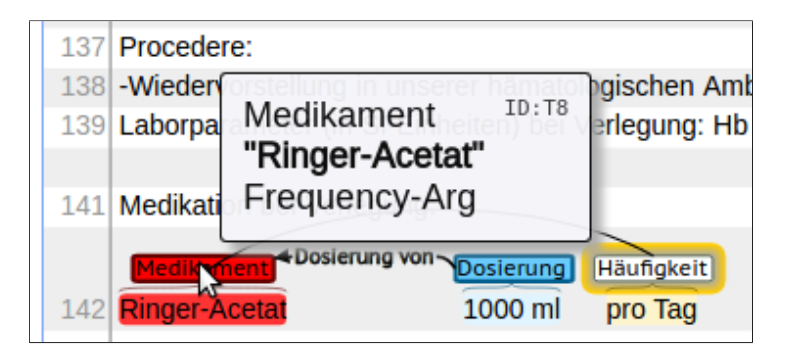
4) Descriptions of medications, including dosage (e.g., 50 mg, 1/2 tablet), frequency (e.g., three times a day), route (e.g., oral or by mouth), duration, and reason;[4]
5) Additional medical categories in terms of content (e.g. descriptions of anatomical locations, medical tests and procedures, treatment methods) and their relations, which relate these categories to each other;
6) Temporal references between categories and their relationships – all references to points in time and the sequence of clinical events – with the aim of being able to automatically map the information contained in the doctor’s letter onto a timeline;
7) Descriptions of the certainty or uncertainty and the exclusion (negation) of statements, for example whether a diagnosis is formulated on a tentative basis or excluded altogether.
The first four of these seven annotation guidelines have now been published at the end of the first phase of the MII. These can be used as a starting point for the cross-consortium project German Medical Textcorpus (GeMTeX). GeMTeX starts in June 2023 and will build a German clinical reference corpus at six university hospitals (Leipzig, TU Munich, Essen, Berlin, Dresden and Erlangen).
Um unsere Webseite für Sie optimal zu gestalten und fortlaufend verbessern zu können, verwenden wir Cookies. Durch die weitere Nutzung der Webseite stimmen Sie der Verwendung von Cookies zu. Weitere Informationen zu Cookies erhalten Sie in unserer Datenschutzerklärung und unserer Cookie-Richtlinie.
Funktional
Always active
Der Zugriff oder die technische Speicherung ist unbedingt für den rechtmäßigen Zweck erforderlich, um die Nutzung eines bestimmten Dienstes zu ermöglichen, der vom Abonnenten oder Nutzer ausdrücklich angefordert wurde, oder für den alleinigen Zweck der Übertragung einer Nachricht über ein elektronisches Kommunikationsnetz.
Vorlieben
Die technische Speicherung oder der Zugriff ist für den rechtmäßigen Zweck der Speicherung von Voreinstellungen erforderlich, die nicht vom Abonnenten oder Nutzer beantragt wurden.
Statistiken
Die technische Speicherung oder der Zugriff, der ausschließlich zu statistischen Zwecken erfolgt.Die technische Speicherung oder der Zugriff, der ausschließlich zu anonymen statistischen Zwecken verwendet wird. Ohne eine Aufforderung, die freiwillige Zustimmung Ihres Internetdienstanbieters oder zusätzliche Aufzeichnungen von Dritten können die zu diesem Zweck gespeicherten oder abgerufenen Informationen allein in der Regel nicht zu Ihrer Identifizierung verwendet werden.
Marketing
Die technische Speicherung oder der Zugriff ist erforderlich, um Nutzerprofile zu erstellen, um Werbung zu versenden oder um den Nutzer auf einer Website oder über mehrere Websites hinweg zu ähnlichen Marketingzwecken zu verfolgen.