
GeMTeX schafft ersten Standard zur De-Identifikation deutschsprachiger medizinischer Dokumente
Im GeMTeX-Projekt der Medizininformatik-Initiative (MII) arbeitet ein interdisziplinäres Team daran, Texte aus der klinischen Routineversorgung für Forschung und Klinik nutzbar zu machen. Ziel ist es, einen der größten Datensätze zur automatischen Verarbeitung medizinischer Texte in deutscher Sprache zu schaffen. Nun hat das GeMTeX-Team einen zentralen Meilenstein erreicht: Forschende der Universitätskliniken Leipzig und Erlangen haben erstmals Annotate für ein Textkorpus veröffentlicht, die als Vorlage für die De-Identifikation deutschsprachiger medizinischer Texte dienen.
Annotate sind Markierungen von Textstellen, die Metadaten zum Inhalt liefern. Diese Markierungen machen die Texte beispielsweise für Anwendungen Künstlicher Intelligenz und Large Language Models nutzbar.
Pilotstudie zur Annotation personenidentifizierender Informationen
Im Prozess der De-Identifikation werden Daten, die Rückschluss auf Personen zulassen, unkenntlich gemacht. Hierfür haben Medizinstudierende der Universitäten Leipzig und Erlangen gemeinsam mit einem Expertenteam aus Linguistik, Medizin und Informatik in einer Pilotstudie 1.438 Annotate auf fiktiven Arztbriefen erstellt. Die Arztbriefe stammen aus dem Graz Synthetic Text Corpus (GRASCCO).
Bei der Annotation hat sich das GeMTeX-Team auf Textstellen fokussiert, die sensible Informationen wie Namen, Daten, Adressen oder Berufe enthalten. Diese Annotationen ermöglichen es, Software so anzupassen, dass personenbezogene Informationen in klinischen Dokumenten automatisch erkannt und verschlüsselt werden können.
Ein Beispiel für die datenschutzgerechte Verarbeitung medizinischer Texte
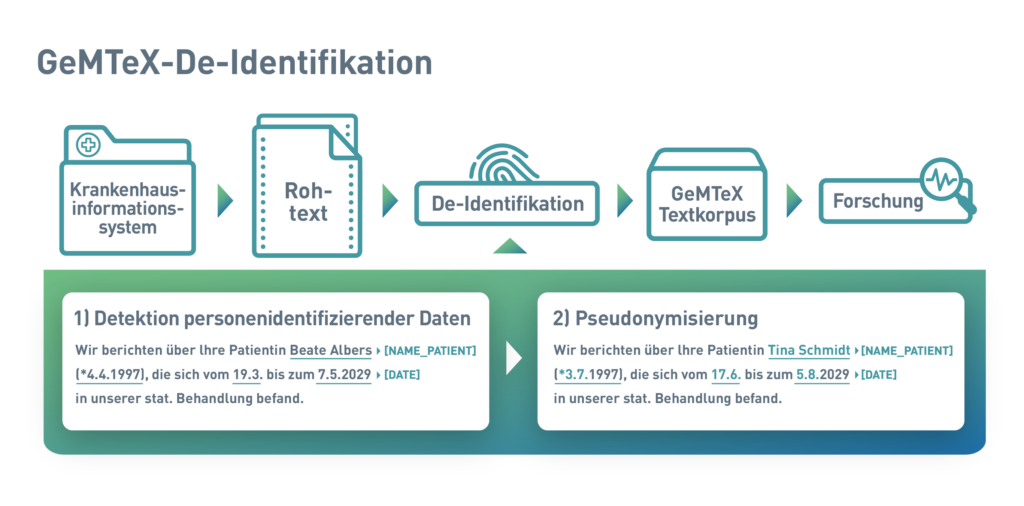
Die annotierten Dokumente wurden auf der internationalen Forschungsdatenplattform Zenodo veröffentlicht und sollen als Vorlage für zukünftige Projekte dienen. Zusammen mit dem annotierten Korpus ist eine Publikation erschienen, die eine Vorgehensweise zur De-Identifikation von medizinischen Dokumenten beschreibt. Die so genannte „De-Idenfikationspipeline“ umfasst folgende Schritte:
- Export der klinischen Texte als Rohdaten aus dem lokalen Krankenhausinformationssystem
- Import auf die Annotationsplattform INCEpTION
- Automatisierte Vorannotation relevanter Textstellen mit personenidentifizierenden Informationen durch die Averbis Health Discovery Pipeline
- Manuelle Überprüfung und Korrektur der Annotationen im Vier-Augen-Prinzip
- Automatisiertes Ersetzen der vorannotierten und korrigierten Daten durch passende Pseudonyme (siehe Abbildung)
Die Ergebnisse der Pilotstudie wurden in einer Publikation zusammengefasst.
Zur Publikation in PubMed
Zum annotierten Textkorpus und den Annotationsleitlinien (Zenodo)