In der Routineversorgung entstehen große Mengen medizinischer Texte, die wertvolle Informationen über Patientinnen und Patienten enthalten. Allerdings können sich Formulierungen, Inhalte sowie Struktur der medizinischen Dokumentationen zwischen verschiedenen Einrichtungen stark unterscheiden und sind somit nicht standortübergreifend für digitale Programme oder Analysen nutzbar. Im SMITH-Konsortium hat sich das NLP-Projekt diesem Problem angenommen und Richtlinien für die Aufbereitung medizinischer Texte veröffentlicht, sodass sie mit Methoden automatischer Sprachverarbeitung (Natural Language Processing, kurz: NLP) für die medizinische Forschung und Versorgung verwendet werden können.
In allen deutschen Krankenhäusern werden bei Verlegung und Entlassung Arztbriefe geschrieben, die den weiterbehandelnden Ärzten Informationen über die jeweiligen Patientinnen und Patienten liefern. Diese Arztbriefe sind ein wesentlicher Bestandteil der medizinischen Dokumentation und beinhalten Informationen über den Grund der Behandlung, Angaben zur Krankheitsgeschichte, Allergien, Vorerkrankungen, Familiendiagnosen, bereits durchgeführte Therapien, bisher verordnete Medikationen und auch Hinweise zur Weiterbehandlung. Informationen dieser Art können nicht nur für die behandelnden Ärztinnen und Ärzte, sondern auch für die medizinische Forschung sowie für die Patientinnen und Patienten selbst von großem Nutzen sein.
Damit diese Texte aus der medizinischen Dokumentation standortübergreifend genutzt werden können, müssen sie für digitale Programme lesbar sein. Die Formulierungen in medizinischen Texten sind jedoch stark abhängig von der Einrichtung, dem medizinischen Fachgebiet und auch von der Person, die sie verfasst. Zudem sind sie in ihrer Form weder strukturell noch inhaltlich reglementiert. Eine automatisierte Erfassung von Details in Texten wie Arzt- und Entlassbriefen, zum Beispiel Beschreibungen von Arzneien, deren Einnahmehäufigkeit (täglich, dreimal am Tag) oder Vergabeform (als Tablette, Tropfen) ist daher ohne vorherige Aufbereitung somit kaum möglich.
Automatisierte Methoden der Textanalyse können die Inhalte solcher Texte sowohl für technische Informationssysteme als auch für behandelnde Ärztinnen und Ärzte sowie Patientinnen und Patienten nutzbar machen. Voraussetzung dafür ist allerdings, dass solche NLP-Systeme auf ausreichendes Textmaterial zugreifen können, um automatische Analysen zu ermöglichen.
Mit Hilfe spezieller Computerprogramme, so genannter Annotationswerkzeuge wie Brat oder INCEpTION, werden Textstellen von geschultem Personal in manuellen Schritten nach bestimmten inhaltlichen Vorgaben markiert. Diese Markierungen, auch Annotationen genannt, enthalten Hinweise auf die Struktur und den Inhalt der Texte und bilden die Grundlage für statistische Modelle, auf denen moderne NLP-Systeme ihre Analysen aufbauen. Die Erstellung solcher Annotationen wird durch Annotationsleitlinien geregelt. Im Rahmen der ersten Förderphase der Medizininformatik-Initiative (MII) wurden mehrere solcher Leitlinien zur Annotation deutschsprachiger Entlassbriefe erarbeitet. Sie konzentrieren sich auf folgende Aufgabenbereiche:
1. Strukturen von Textpassagen, die darüber informieren, ob eine Textpassage z.B. eine Anrede, Anamnese oder die Gabe einer Medikation bezeichnet oder den Verlauf des Krankenhausaufenthaltes beschreibt [1]
2. Personenidentifizierende Merkmale bzw. alle Beschreibungen, die Rückschlüsse auf einen individuellen Patienten erlauben, und somit aus Gründen des Datenschutzes nachfolgend anonymisiert werden müssen [2] (zum Beispiel Personennamen, Adressdaten oder Datumsangaben)
3. Beschreibungen von zentralen inhaltlichen medizinischen Kategorien wie Diagnosen, Symptomen und Befunden [3];
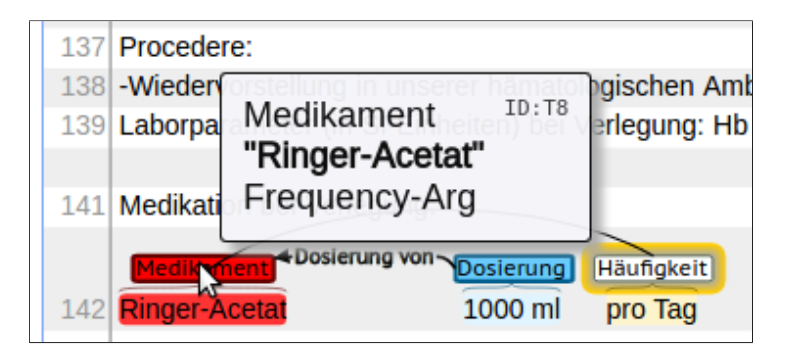
4. Beschreibungen von Medikationen mit deren Dosierung (z.B. 50 mg, 1/2 Tablette), Häufigkeit (z.B. drei Mal täglich), Modus (Beispiel: oral bzw. durch den Mund), Dauer und Grund [4];
5. Zusätzliche inhaltliche medizinische Kategorien (z.B. Beschreibungen von anatomischen Lokalitäten, medizinischen Tests und Prozeduren, Behandlungsmethoden) und deren Relationen, die diese Kategorien zueinander in Beziehung setzen;
6. Zeitliche Bezüge zwischen Kategorien und ihren Beziehungen – alle Angaben von Zeitpunkten und zum Ablauf von klinischen Ereignissen – mit dem Ziel, die im Arztbrief enthaltenen Informationen automatisiert auf einen Zeitstrahl abbilden zu können;
7. Beschreibungen der Sicherheit bzw. Unsicherheit und des Ausschlusses (Negation) von Aussagen, zum Beispiel ob eine Diagnose verdachtsweise formuliert oder gänzlich ausgeschlossen wird.
Die ersten vier dieser sieben Annotationsrichtlinien wurden nun zum Abschluss der ersten Phase der MII bereits veröffentlicht. Diese können als Startpunkt für das konsortiumsübergreifende Projekt German Medical Textcorpus (GeMTeX) genutzt werden. GeMTeX startet im Juni 2023 und baut an sechs Universitätskliniken (Leipzig, TU München, Essen, Berlin, Dresden und Erlangen) einen deutschen klinischen Referenzdatensatz auf.
Um unsere Webseite für Sie optimal zu gestalten und fortlaufend verbessern zu können, verwenden wir Cookies. Durch die weitere Nutzung der Webseite stimmen Sie der Verwendung von Cookies zu. Weitere Informationen zu Cookies erhalten Sie in unserer Datenschutzerklärung und unserer Cookie-Richtlinie.
Funktional
Immer aktiv
Der Zugriff oder die technische Speicherung ist unbedingt für den rechtmäßigen Zweck erforderlich, um die Nutzung eines bestimmten Dienstes zu ermöglichen, der vom Abonnenten oder Nutzer ausdrücklich angefordert wurde, oder für den alleinigen Zweck der Übertragung einer Nachricht über ein elektronisches Kommunikationsnetz.
Vorlieben
Die technische Speicherung oder der Zugriff ist für den rechtmäßigen Zweck der Speicherung von Voreinstellungen erforderlich, die nicht vom Abonnenten oder Nutzer beantragt wurden.
Statistiken
Die technische Speicherung oder der Zugriff, der ausschließlich zu statistischen Zwecken erfolgt.Die technische Speicherung oder der Zugriff, der ausschließlich zu anonymen statistischen Zwecken verwendet wird. Ohne eine Aufforderung, die freiwillige Zustimmung Ihres Internetdienstanbieters oder zusätzliche Aufzeichnungen von Dritten können die zu diesem Zweck gespeicherten oder abgerufenen Informationen allein in der Regel nicht zu Ihrer Identifizierung verwendet werden.
Marketing
Die technische Speicherung oder der Zugriff ist erforderlich, um Nutzerprofile zu erstellen, um Werbung zu versenden oder um den Nutzer auf einer Website oder über mehrere Websites hinweg zu ähnlichen Marketingzwecken zu verfolgen.